爬虫的定义
- 网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,
- 一种按照一定的规则,自动地抓取互联网信息的程序。
- 只要是浏览器能做的事情,原则上,爬虫都能够做
网页三大特征:
1. 网页都有自己唯一的URL
2. 网页都是HTML来描述页面信息
3. 网页都使用HTTP/HTTPS协议来传输HTML数据
爬虫的设计思路:
1. 确定需要爬取的URL地址
2. 通过HTTP/HTTPS协议获取对应的HTML页面
3. 提取HTML页面有用的数据
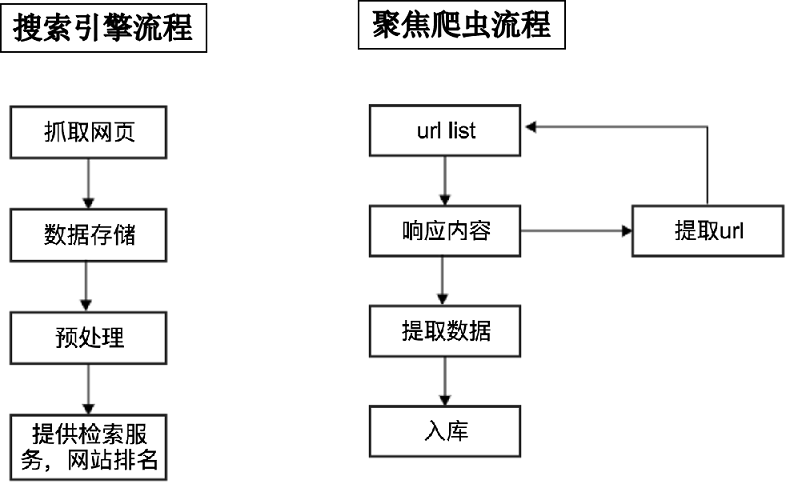
通用爬虫和聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫和聚焦爬虫 两种:
- 通用网络爬虫:
+ 是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。
+ 主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
- 聚焦爬虫(主要使用该方式):
+ 是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:
+ 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
通用爬虫和聚焦爬虫工作流程
HTTP协议简介
概念:通信计算机双方必须共同遵从的一组约定,只有遵守这个约定,计算机之间才能相互通信
- HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
- HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,
在HTTP下加入SSL层
- SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,
保障在Internet上数据传输的安全
+ HTTP的端口号为80
+ HTTPS的端口号为443
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息
URL:统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
• scheme:协议(例如:http, https, ftp)
• host:服务器的IP地址或者域名
• port#:服务器的端口(如果是走协议默认端口,缺省端口80)
• path:访问资源的路径
• query-string:参数,发送给http服务器的数据
• anchor:锚(跳转到网页的指定锚点位置)
HTTP请求方法
主要分为Get和Post两种方法
- GET是从服务器上获取数据,POST是向服务器传送数据
- GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生响应内容,
即“Get”请求的参数是URL的一部分。 例如: http://www.baidu.com/s?wd=Chinese
- POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送
通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等)
请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码
常用的请求报头
1.Host (主机和端口号)
Host:对应网址URL中的Web名称和端口号,用于指定被请求资源的Internet主机和端口号,通常属于URL的一部分。
2.Connection (链接类型)
Connection:表示客户端与服务连接类型
- Client 发起一个包含 Connection:keep-alive 的请求,HTTP/1.1使用 keep-alive 为默认值。
- Server收到请求后:
+ 如果 Server 支持 keep-alive,回复一个包含 Connection:keep-alive 的响应,不关闭连接;
+ 如果 Server 不支持 keep-alive,回复一个包含 Connection:close 的响应,关闭连接。
- 如果client收到包含 Connection:keep-alive 的响应,向同一个连接发送下一个请求,直到一方主动关闭连接。
3. Upgrade-Insecure-Requests (升级为HTTPS请求)
Upgrade-Insecure-Requests:升级不安全的请求,意思是会在加载 http 资源时自动替换成 https 请求,
让浏览器不再显示https页面中的http请求警报。
4. User-Agent (浏览器名称)
User-Agent:是客户浏览器的名称
5. Accept (传输文件类型)
Accept:指浏览器或其他客户端可以接受的MIME(Multipurpose Internet Mail Extensions
(多用途互联网邮件扩展))文件类型,服务器可以根据它判断并返回适当的文件格式。
Accept: */*:表示什么都可以接收。
Accept:image/gif:表明客户端希望接受GIF图像格式的资源;
Accept:text/html:表明客户端希望接受html文本。
Accept: text/html, application/xhtml+xml;q=0.9, image/*;q=0.8:表示浏览器支持的 MIME 类型分别是 html文本、xhtml和xml文档、所有的图像格式资源。
6. Referer (页面跳转处)
Referer:表明产生请求的网页来自于哪个URL,用户是从该 Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站来的等。
7. Accept-Encoding(文件编解码格式)
Accept-Encoding:指出浏览器可以接受的编码方式。
编码方式不同于文件格式,它是为了压缩文件并加速文件传递速度。
浏览器在接收到Web响应之后先解码,然后再检查文件格式,许多情形下这可以减少大量的下载时间。
8. Accept-Language(语言种类)
Accept-Langeuage:指出浏览器可以接受的语言种类,如en或en-us指英语,zh或者zh-cn指中文,
当服务器能够提供一种以上的语言版本时要用到。
9. Accept-Charset(字符编码)
Accept-Charset:指出浏览器可以接受的字符编码。
10. Cookie (Cookie)
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息
11. Content-Type (POST数据类型)
Content-Type:POST请求里用来表示的内容类型。
常用的响应报头(了解)
1. Cache-Control:must-revalidate, no-cache, private。
这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要从新请求服务器,
不能从缓存副本中获取资源。
2. Connection:keep-alive
这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,
客户端可以继续使用这个tcp连接发送http请求。
3. Content-Encoding:gzip
告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
4. Content-Type:text/html;charset=UTF-8
告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。
通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
5.Date: Thu, 02 Jan 2020 06:32:55 GMT
这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。
http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
响应状态码
响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
常见状态码:
- 100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
- 200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
- 300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302
(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。
- 400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。
- 500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
主要分为Get和Post两种方法
- GET是从服务器上获取数据,POST是向服务器传送数据
- GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生响应内容,
即“Get”请求的参数是URL的一部分。 例如: http://www.baidu.com/s?wd=Chinese
- POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送
通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等)
请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码
1.Host (主机和端口号)
Host:对应网址URL中的Web名称和端口号,用于指定被请求资源的Internet主机和端口号,通常属于URL的一部分。
2.Connection (链接类型)
Connection:表示客户端与服务连接类型
- Client 发起一个包含 Connection:keep-alive 的请求,HTTP/1.1使用 keep-alive 为默认值。
- Server收到请求后:
+ 如果 Server 支持 keep-alive,回复一个包含 Connection:keep-alive 的响应,不关闭连接;
+ 如果 Server 不支持 keep-alive,回复一个包含 Connection:close 的响应,关闭连接。
- 如果client收到包含 Connection:keep-alive 的响应,向同一个连接发送下一个请求,直到一方主动关闭连接。
3. Upgrade-Insecure-Requests (升级为HTTPS请求)
Upgrade-Insecure-Requests:升级不安全的请求,意思是会在加载 http 资源时自动替换成 https 请求,
让浏览器不再显示https页面中的http请求警报。
4. User-Agent (浏览器名称)
User-Agent:是客户浏览器的名称
5. Accept (传输文件类型)
Accept:指浏览器或其他客户端可以接受的MIME(Multipurpose Internet Mail Extensions
(多用途互联网邮件扩展))文件类型,服务器可以根据它判断并返回适当的文件格式。
Accept: */*:表示什么都可以接收。
Accept:image/gif:表明客户端希望接受GIF图像格式的资源;
Accept:text/html:表明客户端希望接受html文本。
Accept: text/html, application/xhtml+xml;q=0.9, image/*;q=0.8:表示浏览器支持的 MIME 类型分别是 html文本、xhtml和xml文档、所有的图像格式资源。
6. Referer (页面跳转处)
Referer:表明产生请求的网页来自于哪个URL,用户是从该 Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站来的等。
7. Accept-Encoding(文件编解码格式)
Accept-Encoding:指出浏览器可以接受的编码方式。
编码方式不同于文件格式,它是为了压缩文件并加速文件传递速度。
浏览器在接收到Web响应之后先解码,然后再检查文件格式,许多情形下这可以减少大量的下载时间。
8. Accept-Language(语言种类)
Accept-Langeuage:指出浏览器可以接受的语言种类,如en或en-us指英语,zh或者zh-cn指中文,
当服务器能够提供一种以上的语言版本时要用到。
9. Accept-Charset(字符编码)
Accept-Charset:指出浏览器可以接受的字符编码。
10. Cookie (Cookie)
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息
11. Content-Type (POST数据类型)
Content-Type:POST请求里用来表示的内容类型。
常用的响应报头(了解)
1. Cache-Control:must-revalidate, no-cache, private。
这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要从新请求服务器,
不能从缓存副本中获取资源。
2. Connection:keep-alive
这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,
客户端可以继续使用这个tcp连接发送http请求。
3. Content-Encoding:gzip
告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
4. Content-Type:text/html;charset=UTF-8
告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。
通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
5.Date: Thu, 02 Jan 2020 06:32:55 GMT
这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。
http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
响应状态码
响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
常见状态码:
- 100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
- 200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
- 300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302
(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。
- 400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。
- 500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
1. Cache-Control:must-revalidate, no-cache, private。
这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要从新请求服务器,
不能从缓存副本中获取资源。
2. Connection:keep-alive
这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,
客户端可以继续使用这个tcp连接发送http请求。
3. Content-Encoding:gzip
告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
4. Content-Type:text/html;charset=UTF-8
告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。
通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
5.Date: Thu, 02 Jan 2020 06:32:55 GMT
这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。
http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
常见状态码:
- 100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
- 200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
- 300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302
(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。
- 400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。
- 500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。